2.3 场景表征方法
category
type
status
slug
date
summary
tags
password
icon
场景表征是指在所有可用的场景信息数据中, 提取出对于预测网络有用的数据, 并将其转换为易于模型学习的数据格式. 对于预测网络来说, 最重要的数据是交通参与者的历史轨迹和地图信息, 表达它们的常见方法有:栅格化和稀疏化
2.1.1 栅格化
- 多通道表达

如上图所示, 将历史轨迹和地图信息转换成不同通道的栅格图是在卷积神经网络(CNN)中常见的方法. 不同的通道存储不同的信息, 比如图中的可显示区域存在一个通道中, 道路中心线存储在另一个通道中等等.
- 基于颜色表达

也可以像上图这样, 使用较少的通道数, 人为定义不同的信息来区分. 比如说R,G,B三个通道, 我们将红色定义为agent的历史轨迹信息, 将蓝色定义为地图车道信息, 黑色定义为不可行驶区域等等. 这样就可以缩小栅格图的总数据量.
- 时序信息
那么如何去表达轨迹中的时序信息呢? 可以将按照时序, 使轨迹的颜色由深变浅. 也可以使用前文的多个通道, 或者是多张图片, 来代表不同时序的信息.
- 方向, 速度等
还有类似于朝向角这样的方向信息, 也可以对应的映射到图像信息中去表达. 比如将的方向数据, 对应映射到颜色上去, 比如从红色变成蓝色; 也可以将其映射到亮度上, 比如由暗变亮.
其他诸如速度, 加速度, 转向速度等等不易直接表达成图像的数据, 都可以用类似的方法一一映射到图像中去.
- 优缺点
在早期基于CNN的预测网络中, 这种栅格化的方法非常流行. 因为使用栅格图:
- 天然善于接受基于视觉的输入信息
- 简便的转换场景中的轨迹, 地图信息, 清晰直观
但是它的缺点也很明显:
- 栅格图的存储成本高, 随着场景大小指数增长
- 低分辨率的栅格图, 信息不够明确; 高分辨率的栅格图, 无用细节信息过多
- 过多的映射导致可解释性较差
- 不易可视化数据的信息损失
2.1.2 稀疏化
稀疏化是指将这些图形数据使用向量集表达, 对于轨迹车道线等线段元素, 向量集代表折线段; 对于可显示区域等多边形元素, 向量集代表包围起来的多边形, 这种做法的典型网络是VectorNet.

同时, 车道的转向属性, 车道线属性, 限速等等信息, 都可以直接放入到向量的附属属性中, 输入信息可以完整的保存下来的同时, 只需要存储较小的数据量.
稀疏化表达极大的提升了模型的预测模型的性能, 训练效率和泛化能力, 基本已经成为了场景表征的主流方法.
这些每个对象的向量表达, 可以对每个对象向量集单独编码, 之后再进行聚合, 比如VectorNet使用GNN.
或者是使用联合编码来捕捉他们的交互关系, 比如Transformer.
2.1.2.1 VectorNet: 基于GNN的矢量化编码
(1) 主要贡献
- 第一个矢量化场景上下文和智能体的动力学信息进行行为预测。
- 我们提出了分层图网络以及节点完成辅助任务。
- 在内部行为预测数据集和Argoverse数据集上评估了此方法,与渲染的方法相比达到了同等或更好的性能,并节省了70%的模型尺寸。这个方法在Argoverse上也达到了最优的性能。
(2) VectorNet 模型
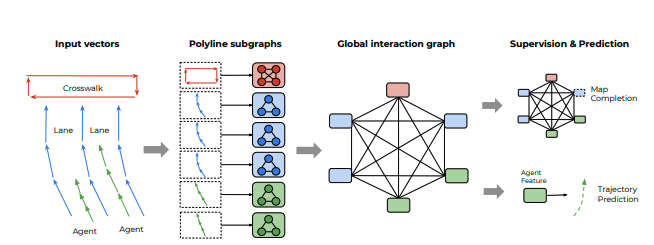
我们提出的矢量网概述。观察到的智能体轨迹和地图特征被表示为向量序列,并传递到局部图形网络以获得多段线级特征。然后将这些特征传递到完全连通的图模型高阶相互作用。我们计算了两种类型的损失:根据智能体对应于节点特征预测未来的轨迹以及其特征被掩盖时预测节点特征。
(3) 轨迹和地图的表示
HD地图中的大多数表示都是样条曲线(如车道)、闭合形状(如交叉口区域)和点(如红绿灯),以及附加属性信息,如当前状态(如交通颜色,道路速度限制)。对于智能体,其轨迹是关于时间的有向样条曲线形式。所有这些元素都可以近似为矢量序列。
对于地图特征,我们选择一个起点和方向,从条线中均匀采样关键点并将相邻的关键点依次连接成向量;对于轨迹,我们可以从t=0开始,以固定的时间间隔(0.1秒)采样关键点,并将它们连接到向量中。给定足够小的空间或时间间隔,生成的多段线可作为地图和轨迹的近似值。
我们的矢量化过程是连续轨迹和vector set、地图信息和vector set之间的一对一映射,尽管后者是无序的。这允许我们可以通过图神经网络进行编码。更具体地说,我们将属于多段线的每个向量视为图中的node,其node表示为
前两个 是起点和终点的坐标,对应于属性特征,如对象类型、轨迹的时间戳或车道的道路特征类型或速度限制;j 是的整数id,表示∈ 。
归一化:为了使输入节点特征相对位置不变,对于目标智能体,作者以目标智能体最后的观测时间下的位置,对所有向量的坐标进行归一化。
(4) 构造多段线子图
为了利用节点的空间和语义局部性,这里采用分层方法,首先在向量层构造子图,其中所有向量节点都相互连接,并且用同一多段线表示。考虑具有节点{}的多段线P将单层子图传播操作定义为:
其中 是l层子网络上面的节点特征, 是输入特征 vi 。
用于转换独立的节点,是一个MLP,所有节点共享参数。一层全连接层后面跟着layer normalization 和ReLU non-linearity。
用于集合周边节点的信息,是一个最大池化的操作。
表示节点和其邻居之间的关系,是一个简单的连接运算。
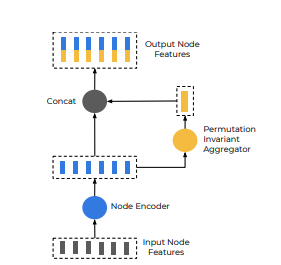
相同多线段下节点的计算流
我们堆叠多层子图网络,其中的权重不同。最后,为了获得polyline级别的特征上,我们计算
其中再一次最大池化。
(5) 高阶交互的全局图
我们现在在全局交互图中考虑polyline node之间的交互,用全局交互图进行建模:
其中 是多线段节点的集合。 对应的单层的图神经网络。A对应节点的邻接矩阵,它能够提供节点之间的距离之类的信息。我们假设A是一个全连接的图,图网络可以表达成self-attention:
其中是节点特征矩阵,,, 是线性投影。
作者将移动的智能体的未来轨从节点中进行解码:
其中是GNN层总数的数目,而是轨迹解码器。为了简单起见,我们使用MLP来解码。
在实现中使用单个GNN层,在推理期间,仅需要计算与agent相对应的节点特征。如果有必要,也可以堆叠多层来建模进行高阶交互。
为了让全局交互图更好地捕捉不同轨迹和map polyline之间的交互,这里引入了一个辅助图完成任务。在训练期间,我们随机掩盖polyline节点的子集的特征,然后尝试将其屏蔽功能恢复为:
其中 是实现MLP解码的节点特征,这些特征不用于推断的时候。是来自全连阶层的节点。为了能够区分独立的polyline节点是对应的特征被隐藏的,计算起始坐标的最小值得到,这些输入的节点特征变成
(6) 整体框架
一旦构建了分层图网络,针对多任务培训目标进行优化
其中,是未来真实轨迹的负高斯对数似然,是在预测的节点特征和真值之间Huber损失,=1.0是平衡两者的损失标量。作者在将polyline节点特征馈送到全局图网络之前对其进行L2归一化。
其他交通参与者采用的是相对偏移,起点是上一帧对目标agent的观测,并且基于上一帧目标agent观测位置的heading建立相对坐标系。
我们对多段线子图使用三个图层,对全局交互图使用一个图层。所有MLP中隐藏单位的数量固定为64。MLP之后是归一化和ReLU非线性。我们以车辆最后观测到的位置为中心,将矢量坐标归一化。VectorNet在8个GPU上同步训练使用Adam optimizer。学习速率每5分钟衰减一次按因子0.3计算,我们训练模型的总时间为25个回合,初始学习率为0.001。
(7) 实验验证
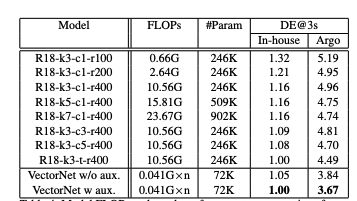
VectorNet相比ResNet-18系列相比,参数量仅为29%,计算量小仅为20%,效果提升18%,真正地实现了更小,更快,更强。
2.1.2.2 基于Transformer的矢量化编码
将在2.5节详细介绍
上一篇
动手学控制理论
下一篇
端到端-理论与实战视频课程
Loading...
.jpg?table=block&id=11acd382-093d-8022-be18-e73973d3469b&t=11acd382-093d-8022-be18-e73973d3469b&width=192&cache=v2)